
【加拿大都市網】 斯坦福大學的Alpaca AI人在許多任務上的表現與驚人的ChatGPT相似,但它建立在一個開源的語言模型上,訓練成本不到600美元。看來這些神一樣的人工智能已經便宜得嚇人了,而且很容易複製。
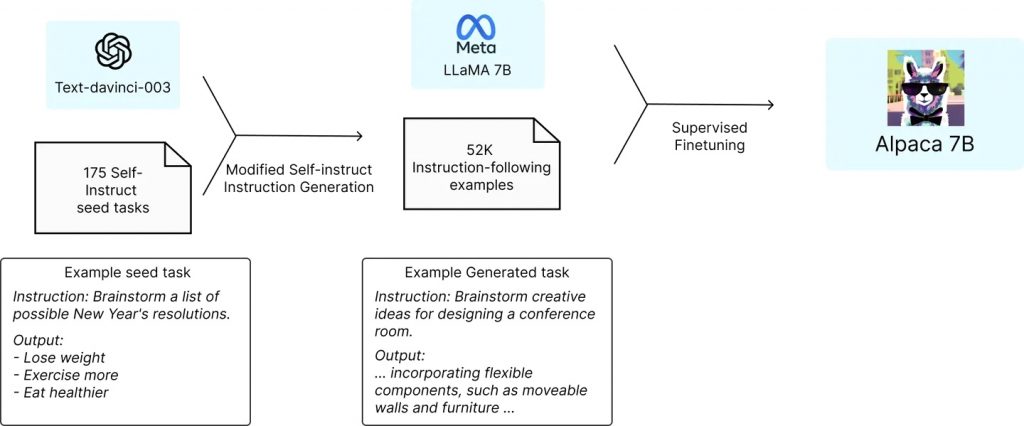
斯坦福大學的一個研究小組從Meta的開源LLaMA 7B語言模型開始,這是現有幾個LLaMA模型中最小和最便宜的一個。在一萬億個「代幣」上進行預訓練,這個小語言模型有一定的能力,但它在大多數任務中明顯落後於ChatGPT;GPT模型的主要成本,甚至主要競爭優勢,主要來自OpenAI在後期訓練中投入的大量時間和人力。讀了十億本書是一回事,但通過大量的問答式對話來教導這些AI的實際工作是另一回事。
因此,隨着LLaMA 7B模型的建立和運行,斯坦福大學的團隊基本上要求GPT採用175個由人類編寫的指令/輸出「組合」,並開始以同樣的風格和格式生成更多的指令/輸出對,每次20個。這是通過OpenAI幫助提供的一個API自動完成的,在很短的時間內,該團隊有大約52,000個對話樣本,用於後期訓練LLaMA模型。生成這些大量訓練數據的成本不到500美元。
然後,他們用這些數據來微調LLaMA模型,這個過程在8台80GB的A100雲端處理電腦上花費了大約3個小時。這方面的花費不到100美元。
接下來,他們對產生的模型進行了測試,他們稱之為Alpaca,與ChatGPT的底層語言模型在各種領域進行對比,包括電子郵件寫作、社交媒體和生產力工具。在這些測試中,Alpaca贏得了90項,GPT贏得了89項。
「鑒於模型規模小,指令跟隨數據量不大,我們對這一結果相當驚訝,」該團隊寫道。「除了利用這個靜態評估集,我們還對Alpaca模型進行了交互式測試,發現Alpaca在不同的輸入集上往往表現得與text-davinci-003 (GPT-3.5)類似。我們承認,我們的評估在規模和多樣性方面可能是有限的」。
該團隊繼續說,如果他們尋求優化過程,他們可能會更便宜地完成這項工作。值得注意的是,任何希望複製人工智能的人現在都可以獲得能力更強的GPT 4.0,以及幾個更強大的LLaMA模型作為基礎,當然也沒有必要停留在52,000個問題。
斯坦福大學的團隊在Github上發佈了這項研究中使用的52,000個問題,以及生成更多問題的代碼,以及他們用於微調LLaMA模型的代碼。該團隊指出,「我們還沒有對Alpaca模型進行微調,使其安全無害」,並要求任何建立Alpaca模型的人報告他們發現的安全和道德問題。
那麼,有什麼可以阻止任何人現在花100美元左右創建他們自家的寵物人工智能,並以他們選擇的方式訓練它?儘管OpenAI的服務條款確實說 「你不能⋯⋯使用服務的輸出來開發與OpenAI競爭的模型」。而Meta說它在現階段只允許學術研究人員在非商業許可下使用LLaMA,儘管這是一個有爭議的問題,因為整個LLaMA模型在公布一周後就在4chan網站上泄露了。
還有一個小組說它已經設法消除了雲端計算成本,在Github上發佈了更多的代碼,可以在Raspberry Pi上運行,並在單個高端nVidia RTX 4090顯卡上在5小時內完成訓練過程。
這一切意味着現在可以建立無限數量的不受控制的語言模型,由具有機器學習知識、不在乎條款和條件或軟件盜版的人建立。
這也給致力於開發自己語言模型的商業人工智能公司潑了一盆冷水;如果所涉及的大部分時間和費用都發生在訓練後階段,而這項工作或多或少可以在回答50或100,000個問題的時間內完成,那麼公司繼續花費這些現金是否有意義?
而對於我們其他人來說,這個軟件的強大功能肯定可以為專制政權、網絡釣魚行動、垃圾郵件發送者或任何其他可疑的人所用。
「精靈已經從瓶子里出來了」,而且似乎已經非常容易複製和重新訓練了,大家要站穩呀!
圖片:Stanford University
T09
